5 AI Innovations Poised to Shape 2024 and Beyond
We explore 5 worthwhile developments that are worth following in 2024, including long inference, synthetic data, alternative architectures, mixture of experts, and online LLMs.

The talented folks over at latent.space have put together a new summary post for January 2024 that is worth reading in full. I am a regular listener of their podcast and they consistently produce smart content with interviews of the developers and leaders building todays Artificial Intelligence.
Right at the top of the article SWYX & ALESSIO explain the challenge we have today:
The most challenging problem for people keeping up on AI is sifting through signal vs noise. Given your total useful knowledge is, by definition, the cumulative sum of still-relevant knowledge, your greatest (possibly only) proxy for useful signal should be the “test of time” estimator: how likely are you to still be caring about {a given model, paper, technique, library, or news item} in 1/3/12/60/120 months from now?
Here's the table they put forward in the article, which I'll summarize below:
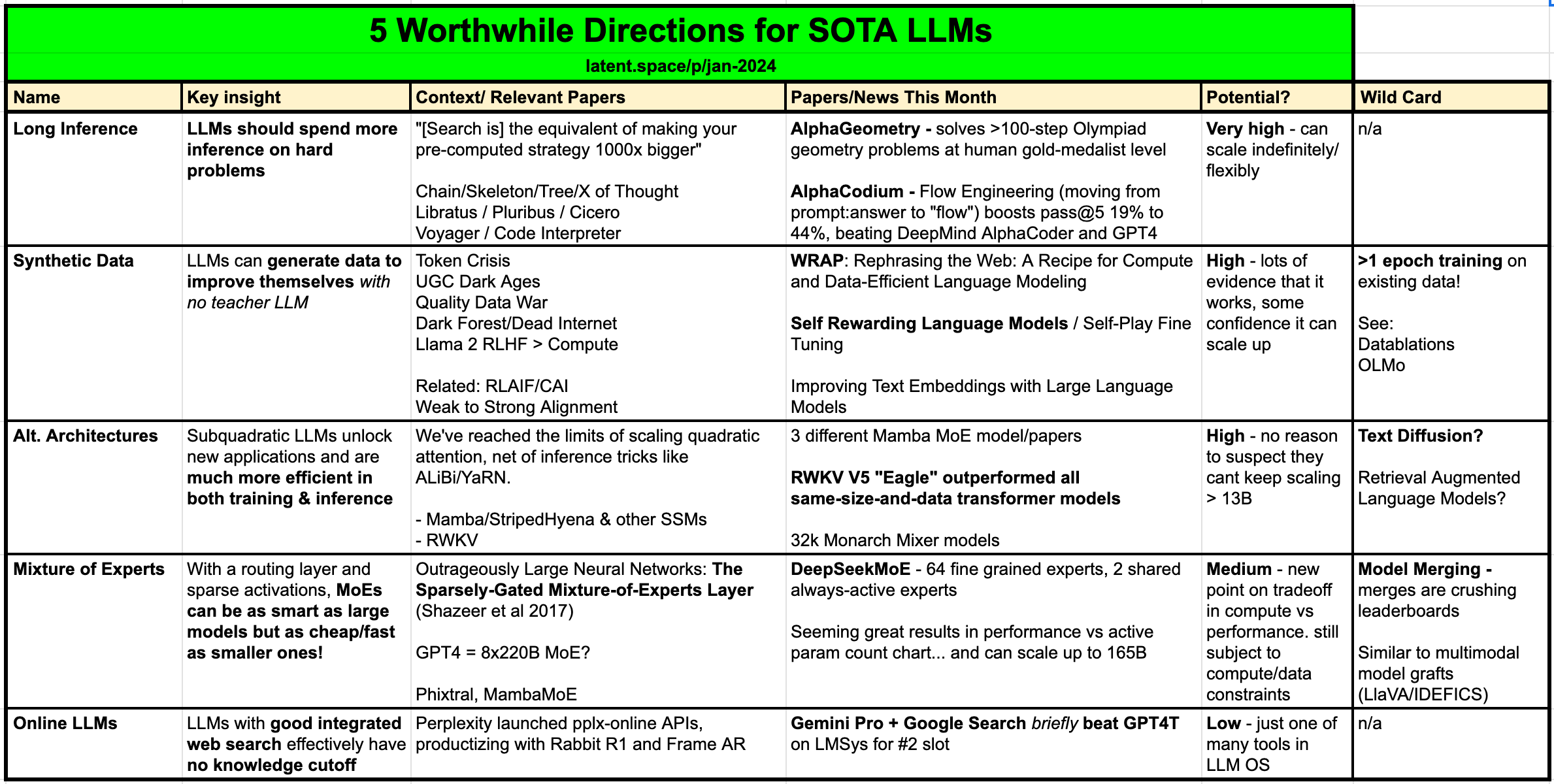
From my view, these are all spot-on, so let's take a minute to discuss each of them.
Long Inference
The concept of Long Inference revolves around the principle that AI systems should allocate more time to deliberating on complex problems than simpler ones. This approach suggests that AI could significantly enhance its problem-solving capabilities by either adhering to a predetermined time budget, which could extend from days to years, or by autonomously managing its resources, which may include employing strategies such as recursion, iteration, or distributing tasks among smaller agent networks.
Basically, just like us humans, we let the AI spend a few more cycles on harder problems - search and planning/researching are both given as examples.
Synthetic Data
Synthetic Data represents a pivotal advancement in the training and enhancement of LLMs, offering a novel approach to overcoming the scarcity of high-quality data necessary for model improvement. This concept is rooted in the ability of LLMs to generate their own training data, thereby bypassing the need for an initial, more intelligent model to synthesize this data from existing sources. The challenge of sourcing "pre-train-quality" data has become increasingly difficult due to factors such as the decline in user-generated content, legal challenges, and the rarity of specific data tokens. Synthetic data generation, therefore, emerges as a crucial strategy in the so-called Quality Data War, offering a means to extend the data availability for LLM training beyond traditional data partnerships.
All that said, in some circles, the success of synthetic data being used to enhance model performance is still being debated. Personally it seems unintuitive that a generative model could both produce "better" data and be competent to spot the fact that it's "better". But AI is weird so I guess we will see.
Alternative LLM Architectures
Alternative LLM Architectures explore the development of models that circumvent the limitations imposed by the quadratic attention costs associated with traditional transformers. These costs have historically restricted the scalability and efficiency of transformers, making it challenging to extend context lengths or enhance performance without incurring prohibitive expenses. However, innovations such as Subquadratic models, including Mamba/StripedHyena State Space Models (SSMs) and RWKV Linear Transformers, have demonstrated promising alternatives that offer both extended context capabilities and improved training/inference efficiency.
The Mamba architecture, in particular has caused a good amount of excitement recently. If we are able to get the same or better resulting models with a cheaper architecture and a far larger context-window, we've got a solid win. Definitely worth watching.
Mixture of Experts
The Mixture of Experts (MoE) approach has emerged as a groundbreaking strategy in the field of machine learning, particularly for enhancing model performance while optimizing computational efficiency. At its core, this method involves the joint training of a routing layer alongside a collection of specialized "expert" models, typically ranging from 8 to 64 in number. However, to save on computational costs and reduce latency during inference, only a subset of these experts, about 2 to 8, are activated. This technique, heralded as a pioneering form of sparsity, allows for significant improvements in model performance.
MoE deserves an article or two all on it's own. Famously, GPT-4 was discovered to be using this approach and the team at Mistral did as well with their Mixtral models . These represent the best of both closed-source and opens-source models, and leveraging this strategy.
Online LLMs
Online LLMs represent an innovative step forward in the evolution of artificial intelligence by integrating real-time web search capabilities directly into their framework. This key feature effectively eliminates the traditional knowledge cutoff that LLMs face, enabling them to access and disseminate the most current information available on the internet. As a result, these models are capable of providing answers that are not only up-to-date but also more relevant and accurate, leading to higher satisfaction ratings from users. For instance, Gemini Pro's integration with Bard and its access to Google search significantly boosted its ELO rating, showcasing the potential of online search integration in enhancing model performance.
This one seems like the most obvious for consumer applications. We want to know current stuff like news, weather, etc. Having access to real-time data is likely to be a tool or capability of future models, when needed. As of the time of this writing I use Perplexity.ai's model which has real-time internet access and only rarely is it more-useful than ChatGPT.
As with any list, this one is likely incomplete. There is so much happening in AI that it's impossible to cover it all. That said, I think this is a smart list and will be using it to help frame new advancements we'll undoubtedly see over the next year.